整理电子书
July 17, 2021这些年来下载了不少电子书,数量慢慢多起来,使用目录整理越来越力不从心. 索性不再管它.通过alfred或是系统的spotlight来进行检索打开阅读,确实方便不少.
但这样有个问题,那就是重复的书很多,影响效率.
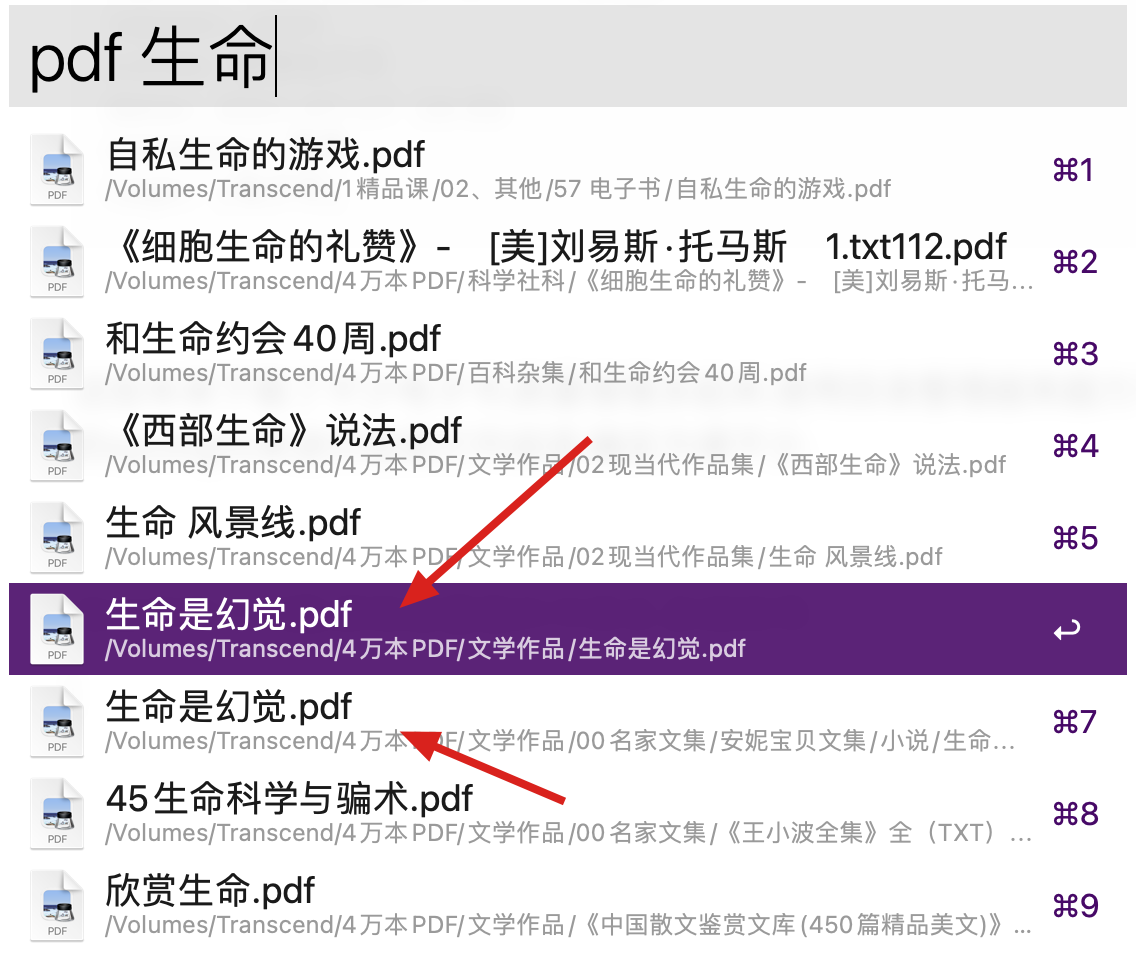
所以需要把一些重复的书删除,以保证搜索结果唯一.
有两个思路,一个就是获取所有文件的摘要md5,如果有多个重复,则只保留一个. 另外一个思路就是考虑到有些重复的书的文件摘要并不相同,所以需要从文件名入手,如果文件名的相似度超过50%,列出来进行二次选择,但是相似度的判断,算法并不那么简单,所以暂时放弃.
摘要去重
1
find . -type f -name "*" -print0 | xargs -0 -I{} md5 "{}" >> file_md5_list.txt
通过上面命令可以将一个目录及子目录所有文件的md5及文件路径信息保存到文件中.像是这样
MD5 (./《yevon_ou文集》_04 天诛篇.pdf) = 2e7e2dbdfe69fde3b2400b894d52a835
MD5 (./《yevon_ou文集》_05 云清篇.pdf) = 0033598a946d5fc12b4e7c1f902d0c84
通过对上面的文件进行简单处理就可以得到文件的md5和文件路径.
生成去重的批处理文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
f1 = File.new("file_md5_list.txt",'r')
a1=[]
a1_md5=[]
f1.each_line do |line|
a1_md5 << line[line.size-33,line.size]
a1 << line
end
#获取有重复的md5
r=a1_md5.group_by{ |e| e }.select { |k, v| v.size > 1 }.map(&:first)
x=''
i=0
r.each do |md5|
i += 1
print "#{i} "
touched = false
a1.each do |line|
if line.include? md5
if not touched
touched = true
next
else
x << "rm \"#{line[5,line.size-42]}\" || true \n"
end
end
end
end
File.open('remove_dup3.sh','w') do |file|
file.puts x
end
简单说明一下
- 遍历file_md5_list.txt 文件,得到两个数组,一个是md5,另一个是文件本身
- 获取到有重复的md5的列表 r
- 遍历r,其中每一个md5都代表着文件里有多行对应,保留第一次出现的.其他的将生成删除命令
x << "rm \"#{line[5,line.size-42]}\" || true \n" - 执行生成的批处理
这里注意尽量不要使用ruby本身去删除文件 ,因为文件数量较多,偶尔会出现文件句柄没来得及释放,删除失败的情况. ||true 是为保证删除一个文件失败时继续执行.